The datacenter of the future will be staffed by a man and a dog.
The man is there to feed the dog.The dog is there to bite the man if he tries to touch anything!
Vick Vaishnavi, back in the day
The datacenter of the future will be staffed by a man and a dog.
The man is there to feed the dog.The dog is there to bite the man if he tries to touch anything!
Vick Vaishnavi, back in the day
Last week the Atlantic published a eulogy for Twitter, which of course was widely reshared via... Twitter.
Uhoh, This content has sprouted legs and trotted off.
Then the reactions started coming in. I think Slate is closest to getting it right:
Twitter is not a social network. Not primarily, anyway. It’s better described as a social media platform, with the emphasis on "media platform." And media platforms should not be judged by the same metrics as social networks.
Social networks connect people with one another. Those connections tend to be reciprocal. […]
Media platforms, by contrast, connect publishers with their public. Those connections tend not to be reciprocal.
I have some conversations on Twitter, but mainly I treat it as a publishing medium. I publish my content, and I follow others who publish there. The interactions on Twitter mainly replace what used to go on in various sites' comments.
The value of Twitter is in making it easy to discover and share content. The "social", meaning Facebook-like, aspects of the platform are entirely secondary to the value of the platform. The more Twitter tries to be Facebook, the worse it gets. It should focus on just being Twitter.
Disclaimer: In case you don’t know already, I work for BMC Software, having joined with the acquisition of BladeLogic. My current role is in marketing for BMC’s cloud computing and data center automation products, including BladeLogic. In other words, if you are looking for a 100% objective take, look elsewhere. The reason this piece is here rather than on a bmc.com site is to make it clear that this is personal opinion, not official corporate communication.
At the turn of the last century, life as a sysadmin was nasty and brutish. Your choice was either to spend a lot of time doing the same few things by hand, generally at the command line, or to spend a lot of time writing scripts to automate those tasks, and then even more time maintaining the scripts, all the while being interrupted to do those same things.
Then along came two automation frameworks, Opsware and BladeLogic, that promised to make everything better. The two tools had somewhat similar origin stories: both were based around cores that came out of the hosting world, and both then built substantial frameworks around those cores. In the end both were bought by larger players, Opsware by HP, and BladeLogic by BMC.
BladeLogic and Opsware both let sysadmins automate common tasks without scripting, execute actions against multiple servers at once, and assemble sub-tasks together to do full-stack provisioning. There were (and are) any number of differences in approach, many of which can still be traced back to the very beginnings of the two companies, but it’s safe to say that they are the two most similar tools in today’s automation marketplace.
Yes, marketplace. Because in the last decade or so a huge number of automation tools have emerged (or matured to the point of usefulness), mainly in the open-source arena. If you are managing tons of OSS Linux boxes, running an OSS application stack, it makes sense to have an OSS config management tool as well.
So far, so good. For a while the OSS tools flew under the radar of the big vendors, since the sorts of people willing to download a free tool and hack Ruby to do anything with it tended not to be the same sorts of people with the six- or seven-figure budgets for the big-vendor tools. As is the way of such things, though, the two markets started to overlap, and people started to ask why one tool was free and the other was expensive. This all came to a head when Puppet Labs published a document entitled "Puppet Enterprise vs BMC BladeLogic". Matthew Zito from BMC responded with An Open Letter to PuppetLabs on BMC’s site, which led to an exchange on Twitter, storified here.
When I was at BladeLogic, I was in pre-sales, and one of my jobs (on top of the usual things like demos, proof-of-concept activities, and RfI/RfP responses) was to help the sales people assemble the business case for buying BladeLogic. This usually meant identifying a particular activity, measuring how much time and effort it took to complete without BladeLogic, and then proposing savings through the use of BladeLogic. Because for some unknown reason prospective customers don’t take vendors’ word for these sorts of claims, we would then arrange to prove our estimates on some mutually-agreed subset of the measured activities.
We would typically begin by talking to the sysadmins and people in related teams. They had generally spent a lot of time scripting, automating and streamlining, and were eager to tell us that there was no reason to buy what we were selling, because there were no further savings to be made. Any requests could be delivered in minutes.
The interesting thing is, we would then go around the corner to the users and ask them how long they typically had to wait for requested services to be delivered. The answers varied, but generally in the range of, not minutes, but two to eight weeks.
Where is that huge discrepancy coming from? Because, depressingly, it’s still the same today, a decade later.
The delay experienced by users is not caused by the fact that sysadmins are frantically flailing away at the keyboard for a full month to deliver something. Credit us sysadmins (for I am still one at heart) with a bit more sense than that. No, the problem is that there are many many different people, functions and teams involved in delivering something to users. Even if each individual step is automated and streamlined and standardised to within epsilon of perfection, the overall process is delayed by the hand-offs between the steps, and even more so when the hand-off isn’t clean and something needs to be reworked, or worse, discussed and argued about.
That is the difference between Puppet and BladeLogic. Puppet is trying to address one - or, in all fairness, several - of those steps, but BladeLogic is trying to address the entire process.
In a wider sense, this is what BMC is trying to do for all of enterprise IT. "Consumerisation of IT" has become a cliché, but it’s true that in the same way that Puppet has moved from a hobbyist market to the IT mainstream, Dropbox has moved from a home user market to a corporate one, AWS has eaten the cloud, and so on. We are living in a Cambrian explosion of tools and services.
Enterprise IT departments and the vendors that serve them cannot compete with these tools, and nor should they. The models of the new entrants give them economies - of scale, of attention, of access - that the traditional model cannot touch. The role for enterprise IT is to provide governance across the top of this extremely diverse and rapidly evolving ecosystem, and fill in the gaps between those tools so that we deliver the correct end product on time, on spec and on budget1.
Sure, use Puppet - and Chef, and Ansible, and SaltStack, and CFEngine, and your home-grown scripts, and maybe even BladeLogic’s BLpackages. Just make sure that you are using them in a way that makes sense, and that meets the users’ needs. At the end of the day, that’s what we are all here for.
Yes, all three. The point of automation is to resolve that dilemma. ↩
So I’m running a little webinar next week (sorry, internal only). It was supposed to have attendance somewhere between ten and twenty people, but the topic is hot, and the invite got forwarded around - a lot. One of the biggest cheeses in the company is attending, or at least, his exec assistant accepted the invite.
On the one hand: yay! An opportunity to shine! Okay, I need to put a lot more thought into my slides and delivery, but this is a chance to put all those presentation techniques into practice.
On the other hand, this has given me an unwelcome insight into what a nightmare it is to run events with large numbers of attendees with "normal" software. Since I have completely lost track of who is attending, I want to at least get a feel for how many people will be in the audience. There doesn’t seem to be an obvious way of doing this in Outlook, so I started googling - and that is when I came across this gem:
If you are the meeting organizer and you want to include each attendee's response to your meeting request, click the Tracking tab, press ALT+PRINT SCREEN, and then paste the image into a Microsoft Office program file.
That is from Microsoft’s own official Office support site, not some random "This One Weird Old Trick Will Help You Get The Most Out Of Outlook". O tempora, o mores...
Apple has always made beta version of its operating systems (both MacOS and iOS) available to registered developers. What was not widely known is that there was also an invitation-only programme for non-developers to get access to pre-release versions of the OSen. This programme has now been opened up for anyone to join.

Here is the link - but I hope you won’t sign up.
Why?
Remember iOS 7? Before the thing was even out, it was being lambasted in the press - including the mainstream press - for being buggy and even bricking people’s phones. It turned out that the "bricking" was simply the built-in auto-expiry of the beta versions. Non-developers who had somehow got hold of an early beta but had not kept up with newer version found out the hard way that betas expire after some time. Also, being beta versions, the quality of the software was - guess what? - not up to release standard yet.
In light of that experience, I do wonder whether opening up OS X even further is a wise move on Apple’s part. I really hope that I don’t have to read on the BBC next week that OS X 10.9.9 is really buggy and unstable, or something equally inane.
I came across this interesting article about the changes that DevOps brings to the developer role. Because of my sysadmin background, I had tended to focus on the Ops side of DevOps. I had simply not realised that developers might object to DevOps!
I knew sysadmins often didn’t like DevOps, of course. Generalising wildly, sysadmins are not happy with DevOps because it means they have to give non-sysadmins access to the systems. This is not just jealousy (although there is often some of that), but a very real awareness that incentives are not necessarily aligned. Developers want change, sysadmins want stability.
Actually, that point is important. Let me emphasise it some more.
Typical pre-DevOps scenario: developers code up an application, and it works. It passes all the testing: functional, performance, and user-acceptance. Now it’s time to deploy it in production - and suddenly the sysadmins are begin difficult, complaining about processes running as root and world-writable directories, or talking about maintenance windows for the deployment. Developers just want the code that they have spent all this time working on to get out there, and the sysadmins are in the way.
From the point of view of the sysadmins, it’s a bit different. They just got all the systems how they like them, and now developers are asking for the keys? Not only that, but their stuff is all messy, with processes running as root, world-writable directories, and goodness knows what. When the sysadmins point out these issues and propose reasonable corrections, the devs get all huffy, and before you know it, the meeting has turned into a blamestorm.

The DevOps movement attempts to address this by getting developers more involved in operations, meaning instead of throwing their code over the proverbial wall between Dev and Ops, they have to support not just deployment but also support and maintenance of that code. In other words, developers have to start carrying pagers.
The default sysadmin assumption is that developers can’t wait to get the root password and go joy-riding in their carefully maintained datacenter - and because I have a sysadmin background, sell to sysadmins, and hang out with sysadmin types, I had unconsciously bought into that. However, now someone points it out, it does make sense that developers would not want to take up that pager…
I wrote a howto on using Skype for my team, and then thought that others could probably take advantage of this too, so here it is. Shout if you have any questions, comments or additions!
These days, most companies above a certain size have some sort of official internal IM/chat solution. In most cases, that solution is Microsoft Communicator or its newer cousin, Lync.
The problem is, the blasted thing just doesn’t work very well, at least on a Mac. Lync goes offline spontaneously at least once every half-hour or so, and it crashes several times a day. It crashes predictably when the Mac resumes from sleep, but it also crashes randomly whenever it feels like it. Finally, Lync is only useful within the company.1 If you need to talk to customers, partners, or contractors, you need an alternative solution.
With that in mind, and in a spirit of Bring Your Own Solution, here is a guide to using Skype for team communications.
Using Skype for basic one-to-one communication is simple enough. Add your team-mates to your contact list, and you can IM or voice chat with them at any time. I would recommend adding team members to your Favorites so they are always available. You can do this by clicking the star icon on each contact, or by right-clicking on their name in the contacts list and choosing "Add to favorites".
Where it gets interesting for a team, though, is that you can set up multi-user chat just as easily. When in a voice or video call, press the plus button in a speech balloon below the contact, and select "Add people…" from the pop-up menu.
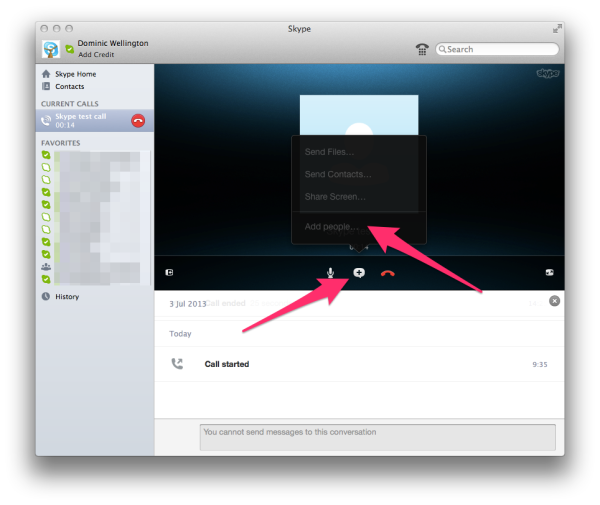
You can do the same in a text chat by selecting the plus button and adding people to the chat. Note that history is persistent, so it might be better to start a new group conversation rather than dropping new people into an existing chat session.
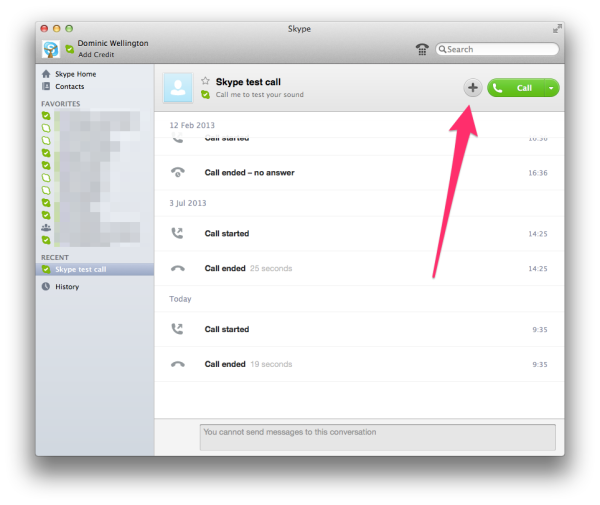
In a conversation, it is also possible to share your desktop. Simply go to the "Conversations" menu and choose "Share screen…". This will allow you to do real-time group edits or share a presentation with other participants in the call, much like WebEx and its ilk.
Skype is not just useful for calling other Skype users. One of the banes of my existence is conference calls which only have US toll-free numbers. Even if I’m in my home country, calling the US from a mobile gets expensive fast, and it’s much worse if I’m roaming. If I can get on wifi, I use Skype to call the US toll-free number. This is free and does not require Skype credit, although performance will depend on your wifi connection. It’s fine for listening to a call, but if you are a primary speaking participant, I would not recommend this approach.
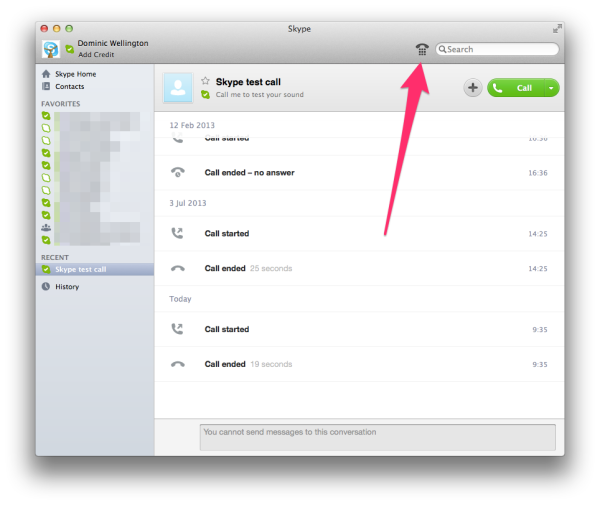
With that caveat out of the way, all you have to do to dial national (not just US!) toll-free numbers with Skype is to bring up the Dial Pad, either by clicking on the little telephone icon beside the search field, or by going to the "Window" menu and selecting "Dial Pad".
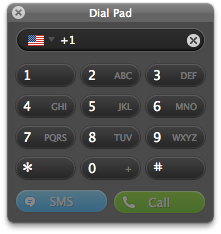
Here you can dial as normal: +1 for the US (or the correct country code for the number you are calling), and then the number. Unfortunately DTMF tones do not work during dialling, so you can’t save conference numbers and PIN codes directly; these have to be dialled each time. Not all conferencing systems seem to receive DTMF tones from Skype even during call setup, so if it’s the first time you are using a particular conference, dial in with time to spare and have a plan B for how you are going to access the call if Skype doesn’t work.
There are mobile Skype clients for all major platforms. They work fairly well, but synchronisation is not guaranteed to be real-time, so if you move from one device to another, you may not be seeing the latest updates in your IM conversations. Also, if you send a message to an offline user, they will not necessarily receive it immediately upon signing on. Anything time-sensitive should go through another medium. At least the delivery receipts in Skype will tell you whether the message reached the intended destination.
I hope this guide has been helpful! Please share any additional tips that you find useful.
It is technically possible for IT departments to "federate" Lync installations between two companies, but that requires lots of work, sign-offs, and back-and-forth to achieve, and anyway only works if both participants are using Lync. ↩
CNET reports that Nike are getting out of the wearable market.
Best comment:
Uh oh, it looks like your embed code is broken.
But seriously.
The tech commentariat is going crazy, passing around the conspiracy theory that Tim Cook, who sits on Nike’s board, killed the FuelBand effort.
Interesting, particularly when you consider that Tim Cook sits on the Nike board.
It’s worth remembering that Tim Cook is on Nike’s board, and that Nike and Apple have long collaborated on fitness.
I don’t think that Tim Cook strong-armed Nike into dropping the FuelBand to favour Apple’s own iWatch. It’s simply that "wearable tech" is not a discrete device. I wore a Jawbone Up! band for more than a year, but when I somehow ripped off the button end against a door frame, I couldn’t be bothered to replace it, and I don’t miss it. The only thing that class of wearables - Fitbit, FuelBand, Up!, they’re all interchangeable for the purpose of this discussion - is generating moderately interesting stats on your everyday level of activity. Sure, it was mildly amusing to get back to the hotel at the end of a long day wandering around Manhattan and upload that I had walked thirty thousand steps, but I knew already that I had done a ton of walking simply by the feel of my legs and feet! When I took actual exercise, the Up! didn’t track it very well, because a wrist-mounted sensor isn’t very good at working out how hard you are cycling or snowboarding.
Instead, I use an app on my iPhone, which does GPS tracking. I still have an ancient - I mean, vintage - 4S, so I don’t have any of the fancy-schmancy M7 sensors in the 5S, but even so, it’s much better at actually tracking exercise than the dedicated devices.
Sure, I could go all in and get one of those heartbeat monitors and what-not, but quite frankly I can’t be bothered. I don’t exercise to beat some abstract number, although I admit to keeping an eye on my average speed on the bicycle. Given the low frequency of my outings (surprise! two kids take up a whole bunch of your free time), I’m quite happy with my 30 km/h average, without needing to plot heartbeat, hydration, etc.
It is looking more and more like Apple is not building a watch at all, and I think that’s exactly the right move. We have spent the last twenty years or so reducing the amount of devices we carry.
Why reverse that trend now?

Nike just saw which way the wind was blowing - maybe with a little help from Tim Cook.

Get ready for the next time you have to change your domain password at work.
For a more serious take, check out XKPasswd. It’s inspired by this XKCD strip.
This post is the follow-up to the earlier post Caveat Vendor.
It’s not easy being an enterprise IT buyer these days. Time was, the IBM sales rep would show up once a year, you would cover your eyes and sign the cheque, and that would be it for another year. Then things got complicated.
Nowadays there are dozens of vendors at each level of your stack, and more every day. Any hope of controlling the Cambrian explosion of technologies in the enterprise went out of the window with the advent of cloud computing. Large companies used to maintain an Office of Vendor Relations, or words to that effect. Their job was to try to keep the number of vendors the company dealt with to a minimum. The rationale was simple: if we have an existing enterprise licensing agreement with BigCo, introducing PluckyStartupCo just adds risk, not to mention complicating our contract negotiations. It doesn’t matter if PluckyStartupCo has better tech than BigCo, we get good enough tech from BigCo as part of our Enterprise Licensing Agreement (all hail the ELA!). On top of that we are pretty sure BigCo is going to be around for the long haul, while PluckyStartupCo is untested and will either go bust or get bought by someone else, either BigCo or one of their competitors. Job done, knock off at five on the dot.
The dependency of business on technology is too close for that approach to work any longer. The performance of IT is the performance of the business, to all intents and purposes. If you don’t believe me, try visiting an office when the power is down or the net connection has gone out. Not much business gets done without IT.
If companies effectively hobble themselves with antiquated approaches to procurement, they leave themselves wide open to being outmanoeuvred by their competitors. When the first non-tech companies built websites, plenty of their competitors thought it was a fad, but those early adopters stole a march on their slow-moving erstwhile peers.
All of this does not even count shadow IT. Famously, Gartner predicted that "By 2015, 35 percent of enterprise IT expenditures for most organizations will be managed outside the IT department's budget." People are bringing their own services, not just the techie example of devs1 spinning up servers in AWS, but business users - Muggles - using Dropbox, Basecamp, Google Hangouts and Docs, Slideshare, Prezi, and so on and on.
First of all, don’t try to stop the train - you’ll just get run down. The only thing you can do is to jump on board and help drive it. Note that I said help: IT can no longer lead from high up an ivory tower. IT leaders need to engage with their business counterparts, or those business users will vote with their feet and go elsewhere for their IT services.
IT leaders can help the business by building a policy framework to encompass all of these various technologies. Most importantly, this framework has to be flexible and assume that new technologies will appear and gain adoption. Users won’t listen if you say "we’ll review doing a pilot of that cool new tech in six months, and if that goes well we can maybe roll it out a year from now". By the time you’ve finished speaking, they’ve already signed up online and invited all their team-mates.
Fortunately, there is a technique that can be used to build these frameworks. It’s called pace layering, and was introduced by Gartner in 2012.
Pace layering divides IT into three layers:
Systems of Record — Established packaged applications or legacy homegrown systems that support core transaction processing and manage the organization's critical master data. The rate of change is low, because the processes are well-established and common to most organizations, and often are subject to regulatory requirements.
Systems of Differentiation — Applications that enable unique company processes or industry-specific capabilities. They have a medium life cycle (one to three years), but need to be reconfigured frequently to accommodate changing business practices or customer requirements.
Systems of Innovation — New applications that are built on an ad hoc basis to address new business requirements or opportunities. These are typically short life cycle projects (zero to 12 months) using departmental or outside resources and consumer-grade technologies.
The idea is that there are parts of the business where the emphasis is on absolute stability, reliability and predictability - the Systems of Record, which are basically the boring stuff that has to work but isn’t particularly interesting. Other areas need to move fast and respond with agility to changing conditions - the Systems of Innovation, the cool high-tech leading-edge stuff. In between there are the Systems of Differentiation, which are about what the company actually does. They need to move fast enough to be relevant, but still be reliable enough to use - often a tough balancing act. The layering looks like this:

If we overlay two common IT methodologies, we start to understand many of the ongoing arguments of the last few years, where it seems that practitioners are talking past each other:

DevOps, Agile, and so on are approaches that work well for Systems of Innovation. Here it is appropriate to "move fast and break stuff", to fail fast, to A/B test things on the live environment. Run with what works; the goal is speed and quickly figuring out the Next Big Thing.
ITIL is the opposite: it’s designed for a cautious approach to mature and predictable systems, with the ultimate goal of maintaining stability. Here, the absolute goal is not breaking stuff; the whole moving fast part is completely subordinate to that goal.
I hear a lot of complaints along the lines of "ITIL is a bottleneck on IT", "ITIL is the anti-Agile", and so on. In the same vein, ITIL sages throw up their hands in horror at some of what the new crowd are getting up to. The thing is, they’re both right.
Use ITIL where it’s appropriate, and be agile where that is appropriate. Try to figure out the demarcation points, the hand-offs, and where you can, by all means take the best of both worlds. You don’t want to have to wait for the weekly Change Advisory Board meeting to make a minor website change, but when something goes wrong, you’ll be thankful for having some sort of an audit trail in place.
So much for operations - but the same applies to planning. The Systems of Record might have a roadmap planned out years in advance, with little reason to deviate from it. The motto here is "if it ain’t broke, DON’T TOUCH IT!". This is the part of the company where mainframes still lurk. Why? Because they work. It’s as simple as that.
On the other hand, the Systems of Innovation are where you want to let a thousand clouds bloom (to coin a phrase). Let people try all those wonderful services I mentioned earlier. The ones that are useful and safe will gradually get adopted further back from the bleeding edge. If something doesn’t make the cut, no matter - you didn’t bet the company on it.
To return to one of my pet arguments, the Systems of Record are virtualised, the Systems of Differentiation are on a private cloud, and the Systems of Innovation are in the public cloud. This way, the strengths of each model fit nicely with each layer’s requirements.
The problems arise if get your layers mixed up - but that’s outside the scope of this post.
Not "debs", whatever autocorrect might think. Although the image is amusing. ↩
Historical site only — new posts are at findthethread.blog